Google DeepMind has just released Gemma 4, its new family of open-weight models under the Apache 2.0 license. Behind the technical announcement lies a major strategic signal: Google is opening access to some of its most powerful models to regain control of the open-source ecosystem in competition with Meta, Mistral AI, and DeepSeek.
At Bridgers, we analyzed this release from the angle that matters for decision-makers and engineering teams: what you can actually deploy, at what cost, and how it changes your AI infrastructure strategy.
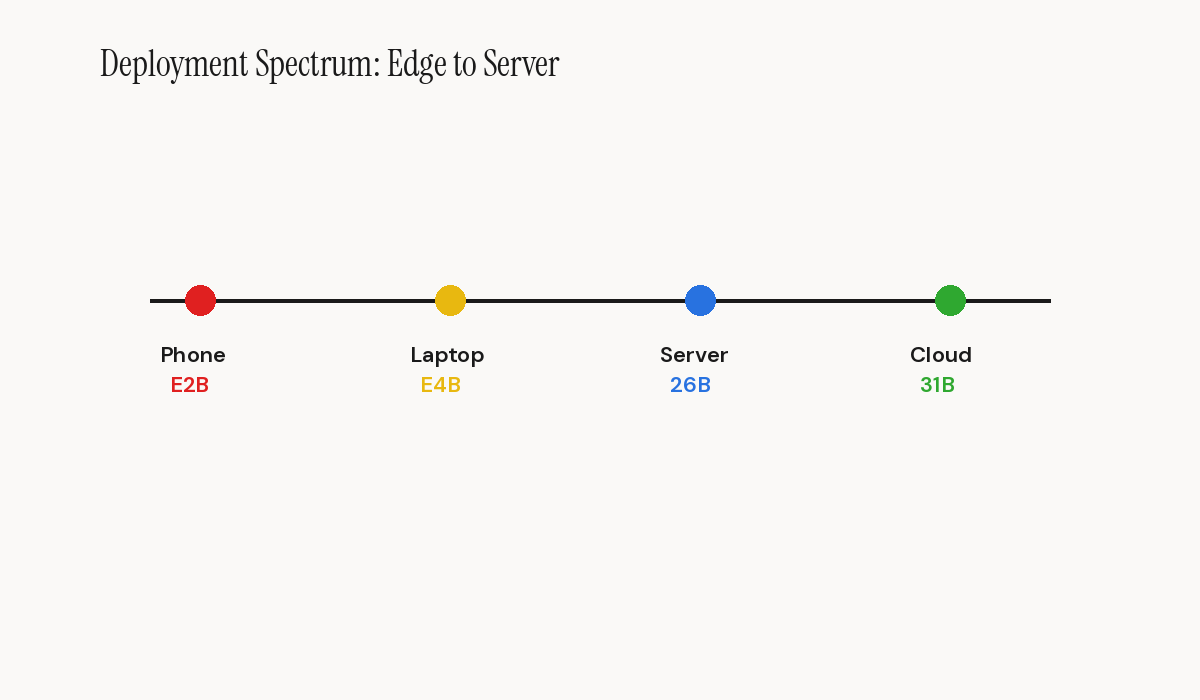
The picture is clear. Gemma 4 does not merely post impressive benchmark numbers on paper. The family of four models covers a use-case spectrum ranging from smartphones to production servers, with a license that eliminates the legal gray areas posed by previous community licenses. This is the first time a player of this scale simultaneously offers edge models, server models, and an MoE architecture, all under Apache 2.0.
To understand the concrete implications, you need to examine each component of this announcement.
Four Models, Four Market Segments: The Full Coverage Strategy
This segmentation is not trivial: it reflects Google's conviction that tomorrow's AI will not live exclusively in the cloud.
The E2B (2.3 billion effective parameters) and E4B (4.5 billion effective parameters) models are built for on-device deployment. They accept text, image, and audio inputs, making them the first truly multimodal open-weight models for the edge. In Q4\_0 quantization, the E2B fits within 3.2 GB of memory. That is compact enough to run on a recent Android phone or a well-equipped Raspberry Pi.
The 26B A4B model uses a Mixture-of-Experts architecture with 25.2 billion total parameters but only 3.8 billion active per token. This ratio is remarkable: you get the quality of a 25-billion-parameter model with the inference speed of a 4-billion-parameter one. The tradeoff, and it is significant, is that all parameters must be loaded into memory for expert routing. Budget 25 GB in SFP8.
Finally, the 31B dense model, with its 30.7 billion parameters and 256K token context window, stands as the flagship. It reaches 85.2% on MMLU Pro, 89.2% on AIME 2026, and 80.0% on LiveCodeBench v6. These numbers place it in the frontier category while remaining deployable on a workstation with two GPUs.
Apache 2.0 Licensing: A Paradigm Shift for Enterprise Projects
introduced restrictions on commercial use and redistribution. Gemma 4 marks a clean break from that model.
The Apache 2.0 license concretely means you can modify the model, redistribute it, integrate it into a commercial product, and even sell it without negotiating additional licensing. For companies operating in regulated sectors such as finance, healthcare, and defense, this legal clarity removes a major adoption barrier.
Google explicitly mentions \"digital sovereignty\" in its launch communications. The term is deliberate. It directly addresses European companies subject to GDPR and sector-specific regulations requiring full control over data and processing infrastructure.
For an agency like Bridgers, which supports clients in deploying AI solutions, this evolution considerably simplifies the legal architecture of projects. No more maintaining a compliance analysis specific to the model license. Apache 2.0 is a standard understood by every legal department.
The comparison with competitors is telling. Meta Llama uses a community license with restrictions beyond 700 million monthly users. Mistral applies different licenses depending on the model. DeepSeek operates under a permissive license but with governance questions tied to its Chinese jurisdiction. Google cuts through the ambiguity by adopting the most open standard available.
Benchmarks Dissected: Where Gemma 4 Excels and Where It Falls Short
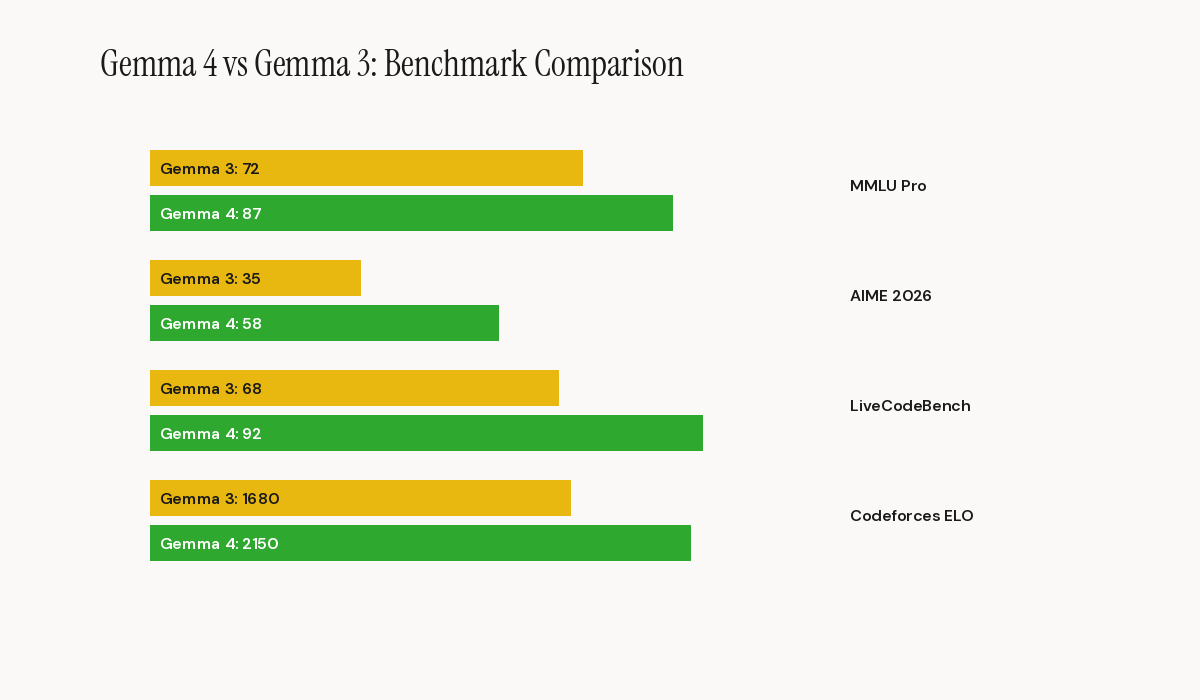
In mathematical reasoning, the 31B model reaches 89.2% on AIME 2026 without tools. That is a remarkable score for a model of this size. The 26B A4B MoE follows closely with 88.3%, confirming the effectiveness of the Mixture-of-Experts architecture for complex reasoning tasks.
In coding, the 31B scores a Codeforces ELO of 2150 and 80.0% on LiveCodeBench v6. For perspective, Gemma 3 27B plateaued at 110 Codeforces ELO and 29.1% on LiveCodeBench. The performance jump is an order of magnitude.
In vision, results on MMMU Pro (76.9% for the 31B) and OmniDocBench (0.131 average edit distance) position Gemma 4 as a serious contender for document processing and visual analysis use cases.
The relative weakness lies in agentic tasks. The 31B's Tau2 score (76.9%) is solid but remains below the most advanced proprietary models. For complex multi-step workflows, Gemma 4 will likely require more robust scaffolding than closed frontier solutions.
For the edge models, results are equally notable. The E4B reaches 69.4% on MMLU Pro and 52.0% on LiveCodeBench v6. These scores would have been considered frontier eighteen months ago and are now accessible in a 4.5-billion-parameter model fitting within 5 GB of memory.
Local Deployment: Memory Planning and Infrastructure Choices
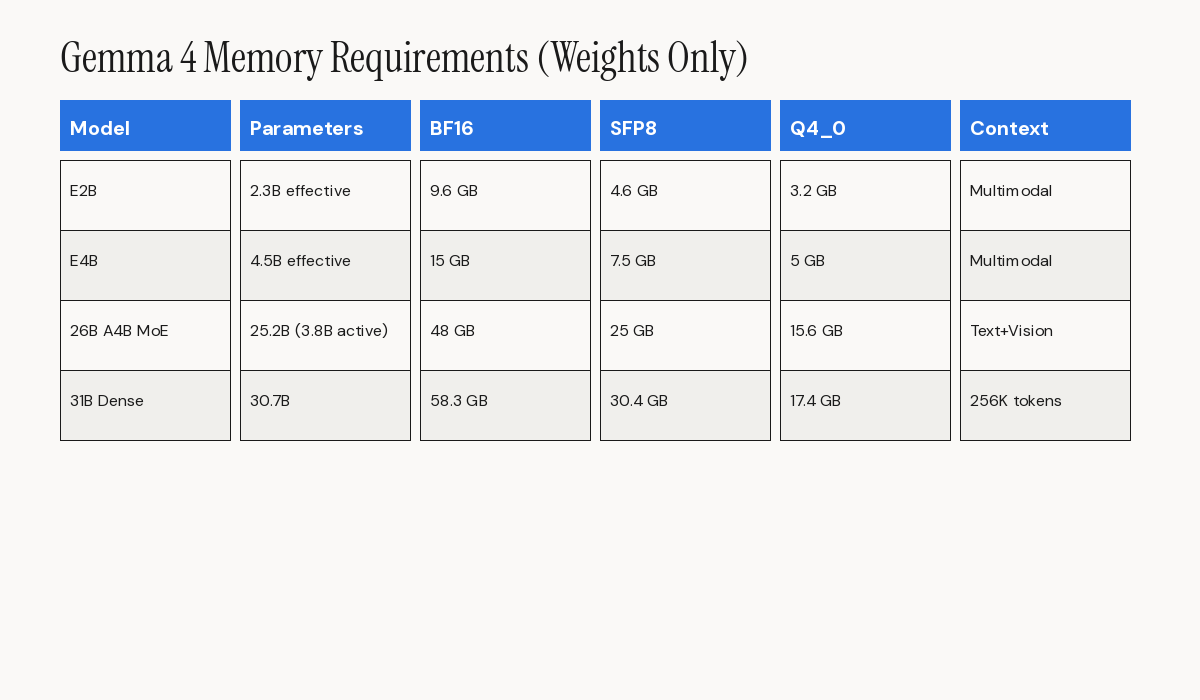
Google's transparency about hardware requirements. Here is the memory planning table for weights alone.
For the E2B: 9.6 GB at BF16, 4.6 GB at SFP8, 3.2 GB at Q4\_0. For the E4B: 15 GB at BF16, 7.5 GB at SFP8, 5 GB at Q4\_0. The 31B dense requires 58.3 GB at BF16, 30.4 GB at SFP8, and 17.4 GB at Q4\_0. The 26B A4B MoE needs 48 GB at BF16, 25 GB at SFP8, and 15.6 GB at Q4\_0.
These figures exclude the KV cache for long contexts and software overhead. For a production deployment with a 128K token context, plan for a 1.5x to 2x multiplier on these estimates.
Distribution is broad: Hugging Face, Kaggle, Ollama, Google AI Studio, AI Edge Gallery, and Android AICore Developer Preview. The serving ecosystem is already in place with vLLM, llama.cpp, MLX, and SGLang. This coverage significantly reduces time-to-deployment for teams.
Strategic Implications for Teams Building With AI
For startups and SMBs, the 26B A4B MoE model offers an extraordinary quality-to-cost ratio. With only 3.8 billion active parameters per token yet near-31B performance on many benchmarks, it enables serving high-quality queries on a reduced inference budget. If you are building an AI product and API costs are a limiting factor, this model deserves your immediate attention.
For large enterprises, the combination of Apache 2.0 plus local deployment plus 256K token context opens the door to internal assistants running entirely on-premises. Regulated sectors like banking and insurance, which could not send sensitive data to third-party APIs, now have a credible alternative to proprietary models.
For mobile application developers, the E2B and E4B models with native audio support enable envisioning embedded voice assistants operating offline. This is a use case that was previously reserved for proprietary models from Apple and Google integrated into the operating system.
What Gemma 4 Does Not Solve: Limitations to Keep in Mind
only produces text output. No image generation, no speech synthesis, no video. For complete multimodal pipelines, you will need complementary models. Teams should plan their architectures accordingly, treating Gemma 4 as the reasoning and understanding layer while sourcing generation capabilities from specialized models.
Performance on long-horizon agentic tasks remains behind specialized models like GLM-5.1 or cutting-edge proprietary solutions. If your use case involves autonomous agents running across hundreds of iterations, Gemma 4 alone will likely not suffice.
Finally, language support deserves attention. Audio benchmarks are only available for English at this stage. For multilingual deployments, particularly in French, additional testing will be necessary before validating production quality.
Conclusion: A Cornerstone for Your Open-Source AI Strategy
Google considers open source a first-tier strategic vector, not a byproduct of its research.
For technical teams, the question is no longer whether open-weight models can compete with proprietary solutions. The question is how to optimize your stack to capitalize on this new reality. The answer will likely involve a hybrid architecture: Gemma 4 locally for sensitive and recurring tasks, frontier models via API for the most demanding use cases.
The ecosystem momentum is also worth noting. Google reports over 400 million downloads across the Gemma family since the first generation and more than 100,000 community variants in the \"Gemmaverse.\" This installed base means extensive community support, readily available fine-tunes for specialized tasks, and a wealth of deployment guides and optimization tips. For teams evaluating open-weight models, this ecosystem maturity reduces the risk of adoption compared to newer, less battle-tested alternatives.
At Bridgers, we recommend teams start with the 26B A4B MoE model to evaluate the performance-cost ratio on their specific use cases. It offers the best compromise between quality, inference speed, and memory footprint. If your results confirm the official benchmarks, you may be holding the central piece of your AI infrastructure for the months ahead.


