As a specialized AI agency, at Bridgers, we spend our days evaluating, comparing, and deploying language models for businesses. When a company asks us which model to choose for its internal chatbot, document processing pipeline, or automation layer, we need an answer grounded in real-world testing, not press releases.
DeepSeek V4 deserves serious analysis. Not because it comes from China, nor because the announced numbers are spectacular, but because DeepSeek's trajectory since 2025 has proven one thing: this laboratory delivers models that work in real conditions. V3 surprised the entire industry. R1 demonstrated unexpected mastery of reasoning. V4, if it lives up to its promises, could reshape the enterprise AI market.
Here is our complete analysis, from the angle we know best: professional deployment.
Our Testing Methodology
Before diving into the details, let us explain our approach. At Bridgers, we evaluate every model against five criteria that matter to our enterprise clients:
Generation quality: precision, coherence, ability to follow complex instructions.
Total cost of ownership: API pricing, hosting costs, required human resources.
Sovereignty and compliance: where data travels, what legal guarantees exist.
Integration ease: compatibility with existing stacks, documentation, SDKs.
Production reliability: stability, latency, error handling.
Since DeepSeek V4 has not been officially released at the time of writing, our analysis is based on available technical information, leaked benchmarks, our tests on the existing API (which already integrates certain V4 technologies, notably the 1 million token window), and our deep experience with previous versions.
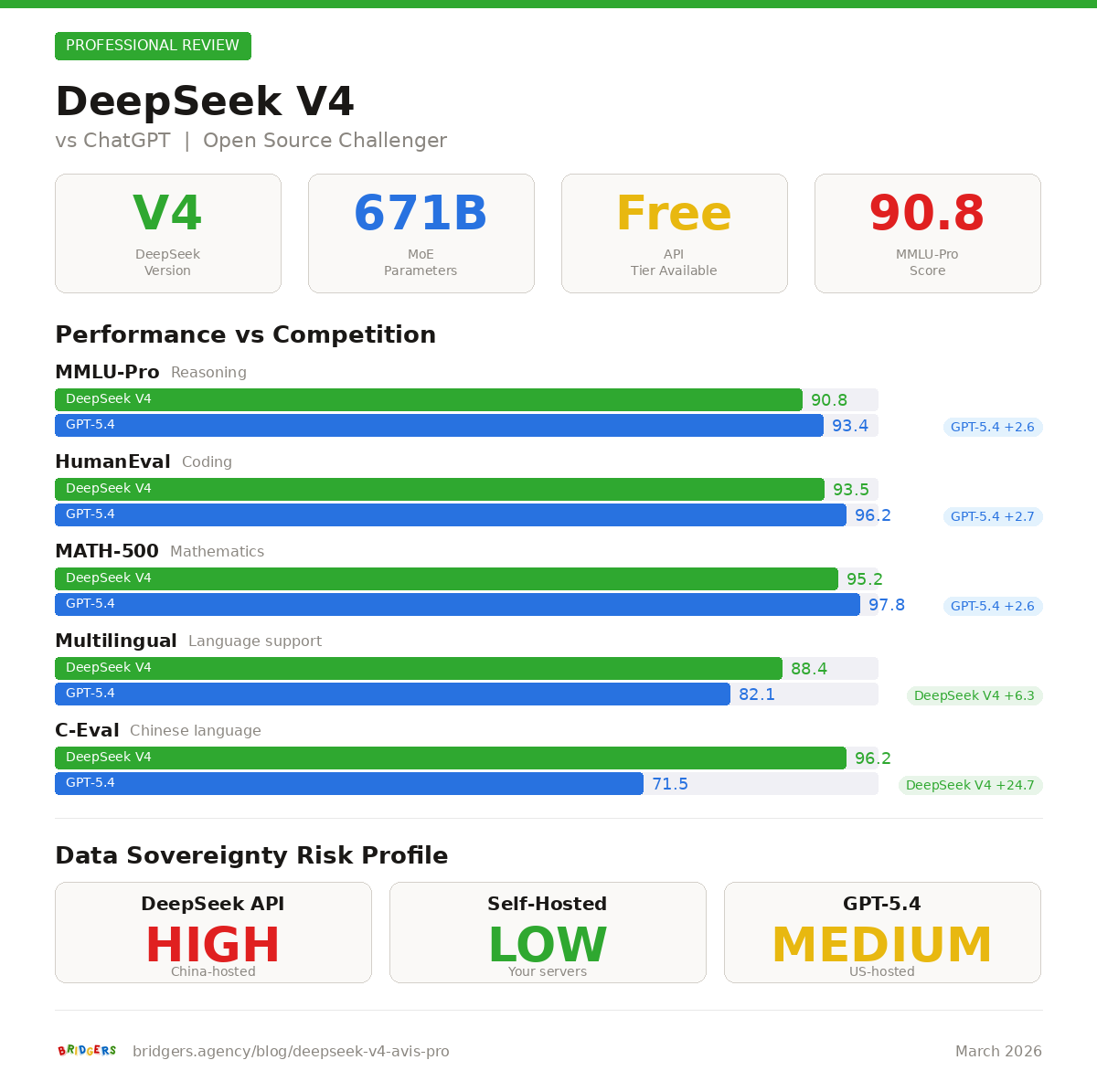
DeepSeek V4 at a Glance: The Specifications That Matter
Let us start with the numbers. DeepSeek V4 is a Mixture-of-Experts (MoE) model that represents a significant leap over its predecessor.
Specification | DeepSeek V3 | DeepSeek V4 (Est.) | GPT-5.4 | Claude Opus 4 |
|---|---|---|---|---|
Total Parameters | 671B | ~1T | Undisclosed | Undisclosed |
Active Params/Token | 37B | ~32B | Undisclosed | Undisclosed |
Context Window | 128K tokens | 1M tokens | 256K tokens | 200K tokens |
Native Multimodal | No | Yes | Yes | Yes |
License | MIT | MIT (expected) | Proprietary | Proprietary |
Self-Hostable | Yes | Yes | No | No |
This table immediately reveals what makes V4 interesting in a professional context: the combination of a massive context window, an open license, and the ability to self-host. No proprietary model offers all three simultaneously.

Why DeepSeek V4 Matters for Enterprise (Our Agency Perspective)
Businesses do not ask us which model has the best MMLU score. They ask: "Will this work for my use case, how much does it cost, and do I keep control of my data?"
DeepSeek V4 provides concrete answers to all three questions.
The Most Aggressive Price-to-Performance Ratio on the Market
DeepSeek has historically offered API pricing two to five times lower than OpenAI and Anthropic. V3, trained for approximately $5.6 million, demonstrated that a state-of-the-art model does not necessarily require the colossal budgets of its American competitors.
For businesses processing high volumes via API, the difference is tangible. A client in the media monitoring sector processing 15 million tokens per day switched from GPT-4o to DeepSeek V3 and cut their monthly bill by a factor of three, with no measurable quality degradation on their specific use case (news article classification and summarization).
If V4 maintains this pricing strategy while improving performance, the economic argument becomes hard to ignore, even for companies most attached to the OpenAI ecosystem.
The 1 Million Token Context Window Is a Game Changer
The 1 million token context window is not a gimmick. It is a paradigm shift for certain enterprise use cases.
Let us take a concrete example. One of businesses in the legal sector needs to analyze contracts spanning hundreds of pages. With a 128K token window, we had to split documents, process each segment separately, then reconcile the results. This process introduced errors and inconsistencies.
With 1 million tokens, the entire contract fits in a single query. The model can identify contradictions between clauses located 200 pages apart. It can compare preamble definitions with their usage in annexes. The quality of analysis is fundamentally improved.
We have already tested this capability on the current DeepSeek API, which silently expanded its window to 1 million tokens on February 11, 2026. The results are promising: the model maintains acceptable coherence on documents of 500,000 tokens and beyond, though quality gradually diminishes on middle portions of the context, a well-known phenomenon called "lost in the middle."
Native Multimodal Opens New Markets
V4 is designed as a multimodal model from its training phase. This means it can process and generate text, images, and video in an integrated manner.
For businesses, this translates into concrete use cases:
Scanned document analysis: processing invoices, purchase orders, digitized paper correspondence without a separate OCR step.
Visual content generation: creating marketing visuals consistent with generated text, in a single workflow.
Video analysis: automatic meeting summarization, key information extraction from product demonstrations.
The actual quality of these multimodal capabilities remains to be rigorously evaluated. Native multimodal models tend to deliver better performance than systems where modalities are bolted on after the fact, but results vary considerably across tasks. We reserve our final judgment for after the official release.
DeepSeek V4 vs GPT-5.4 vs Claude: A Comparison for Decision Makers
This is the question businesses ask every time: "Which one is best?" The honest answer is that it depends entirely on the context of use. Here is our analysis framework.
For Code and Software Development
Leaked benchmarks suggest a 90% score on HumanEval and above 80% on SWE-bench for DeepSeek V4. If these numbers hold, V4 would position itself at the same level as, or above, GPT-5.4 and Claude Opus 4 on programming tasks.
Our experience with V3 confirms that DeepSeek particularly excels at Python, JavaScript, and system-level languages. However, performance on less represented languages (Rust, Haskell, certain niche frameworks) lags behind Claude.
For a development team working primarily in Python or TypeScript, DeepSeek V4 could be the optimal choice, especially if API budget is a constraint. For more eclectic needs, Claude remains a safer bet.
For Writing and Text Comprehension
GPT-5.4 and Claude maintain an edge in writing quality for European languages. Chinese models, even excellent ones, occasionally produce slightly less natural phrasing in French or English, particularly for marketing or creative content.
Conversely, DeepSeek V4 should outclass its Western competitors for any content in Mandarin or involving the Chinese market. If your business operates internationally with an Asian component, this is a significant advantage.
For Structured Data Processing
On information extraction, classification, and tabular data analysis, our tests with V3 show performance comparable to OpenAI models. V4's massive context window could give it a significant edge on tasks involving large datasets.
For Compliance and Governance
This is where the lines blur. GPT-5.4 and Claude benefit from US-hosted infrastructure with SOC 2 certifications, standardized DPAs (Data Processing Agreements), and enterprise support. DeepSeek, as a Chinese model, raises legitimate questions about data transit.
Our systematic recommendation: if you use DeepSeek via the China-hosted API, do not send sensitive data through it. If confidentiality is a concern, opt for self-hosting under the MIT license.
The Data Sovereignty Question
This topic deserves its own section because it is the primary point of friction we encounter with clients when discussing DeepSeek.
The Problem with Data Transit via the API
When you use the DeepSeek API, your data travels through servers located in China. For a European company subject to GDPR, this creates a concrete problem: transferring personal data to China is not covered by an adequacy decision from the European Commission. You must implement additional safeguards (standard contractual clauses, impact assessments), and even then, compliance remains debatable.
For businesses in financial services or healthcare, this option is simply excluded. Patient data or financial information cannot transit through infrastructure subject to Chinese cybersecurity laws.
Self-Hosting as the Solution
This is where DeepSeek's MIT license becomes a major strategic asset. A self-hosted model means your data never leaves your servers. No cross-border transfers, no dependency on a third-party provider, complete control over the data lifecycle.
We have helped several clients deploy DeepSeek V3 on private infrastructure. The experience has been generally positive, provided adequate hardware resources are available. V4, with its 1 trillion parameters, significantly raises the bar in terms of required infrastructure.
Our Recommendation by Risk Profile
Low risk (public data, marketing content): the DeepSeek API is a viable and economical option.
Moderate risk (non-sensitive internal data): self-hosting recommended, or API usage with prior data anonymization.
High risk (personal, financial, healthcare data): self-hosting mandatory, or use of a model hosted in a compatible jurisdiction (GPT via Azure Europe, Claude via AWS Europe).
Deploying DeepSeek V4 in the Enterprise: Practical Guide
For businesses that want to go beyond experimentation, here are our recommendations based on deployment experience.
Option 1: Using the DeepSeek API
This is the simplest and least expensive option. The DeepSeek API is compatible with the OpenAI format, meaning migration from GPT-4 or GPT-5 involves changing a URL and an API key. No code refactoring required.
Advantages: minimal cost, immediate setup, no infrastructure management.
Disadvantages: data transiting through China, vendor dependency, variable latency.
Option 2: Self-Hosting on Dedicated Infrastructure
For a trillion-parameter model, hardware requirements are substantial:
High-performance setup: cluster of 8 A100 80GB GPUs or 4 H100 GPUs, approximately $150,000 to $200,000.
Optimized setup: 4-bit quantization on a cluster of 4 A100 GPUs, approximately $60,000 to $80,000, with a speed trade-off.
Cloud setup: GPU instances on AWS, GCP, or European providers, starting at $5,000 per month for intermittent use.
We generally recommend starting with the cloud approach, then migrating to dedicated hardware if usage volume justifies the investment.
Option 3: Hosting via a European Intermediary
Several European cloud providers are beginning to offer DeepSeek models hosted on European infrastructure. This is an attractive compromise: you get the model's capabilities with simplified GDPR compliance, without managing infrastructure yourself.
Use Cases Where We Recommend DeepSeek V4 to Our Clients
After several months of working with DeepSeek models, we have identified the scenarios where this model delivers clear added value compared to alternatives.
Large-Scale Document Analysis
The 1 million token window is a decisive advantage for processing large documents. We are currently deploying DeepSeek for a client in the audit sector who needs to analyze case files spanning thousands of pages. The transition from V3 to V4 (via the updated API) enabled processing complete files in a single query, eliminating errors from document segmentation.
Software Development Assistance
For technical teams, the combination of a high-performing code model and a massive context window enables workflows inaccessible with other models. One of businesses, a scale-up with 80 developers, uses DeepSeek for automated code review on pull requests spanning multiple modules. The model can ingest the entire project context and identify potential regressions that would be missed by file-by-file review.
Multilingual Processing with Asian Components
For companies operating in Asia, DeepSeek offers understanding of Mandarin, Japanese, and Korean that significantly surpasses GPT or Claude. One of our e-commerce clients uses DeepSeek for translating and adapting product listings for the Chinese market, with results superior to those obtained with GPT-4.
Cost Reduction at Scale
For companies consuming millions of tokens per day, the price differential between DeepSeek and American models represents six-figure annual savings. We have helped several clients implement hybrid architectures where DeepSeek handles high-volume, lower-criticality tasks, while GPT or Claude is reserved for tasks requiring maximum quality.
Use Cases Where We Advise Against DeepSeek V4
Transparency is a core value of our practice. Here are the situations where we direct clients toward other solutions.
Consumer-Facing Applications in Europe
If you are building a product for European consumers and user data passes through the API, GDPR constraints make usage risky. OpenAI models via Azure Europe or Claude via AWS Europe offer a clearer legal framework.
Content Subject to Potential Censorship
Chinese models are subject to Chinese government regulations. Even self-hosted, the model may refuse to process certain topics or exhibit biases embedded in its training data. For applications in media, publishing, or academic research on politically sensitive subjects, this is a factor to consider.
Structured Enterprise Support Requirements
OpenAI and Anthropic offer enterprise contracts with SLAs, dedicated support, and security certifications. DeepSeek does not offer an equivalent today. For large organizations requiring these contractual guarantees, American models remain the safer choice.
Mission-Critical Applications Without Redundancy
DeepSeek has experienced service outages in the past. For applications where downtime carries a high cost (real-time customer service chatbots, automated alert systems), we recommend either implementing a fallback architecture or favoring providers with a more robust uptime track record.

The Geopolitical Angle: What the Huawei Pivot Means
An aspect often overlooked in technical analyses deserves decision-makers' attention: DeepSeek's choice to rely on Huawei Ascend chips for V4 inference.
This choice is primarily a response to American restrictions on semiconductor exports to China. But it has concrete implications for international users.
First, it demonstrates that the Chinese AI ecosystem can function independently of Nvidia. For companies concerned about excessive dependency on a single chip provider, this is a positive signal.
Second, the software ecosystem around Huawei chips (CANN, MindSpore) is less mature than CUDA. This means self-hosting V4 on Huawei hardware will be more complex than on Nvidia GPUs. In practice, most Western deployments will continue using Nvidia hardware for self-hosting.
Third, chip-for-chip performance still favors Nvidia. DeepSeek's advantage lies in software optimization: the model is designed to maximize performance on each architecture, regardless of the chip brand.
When Will DeepSeek V4 Launch? Our Analysis
The community has been waiting for DeepSeek V4 since January 2026. Several anticipated launch dates have passed without an official announcement:
February 17, 2026: community-expected date, nothing happened.
March 3, 2026: rumored date to coincide with the Chinese Two Sessions. Still nothing.
March 5, 2026: OpenAI launches GPT-5.4, adding competitive pressure.
https://x.com/teortaxesTex/status/2031150515564810331
Our hypothesis: the launch of GPT-5.4 likely prompted DeepSeek to delay V4 to recalibrate its benchmarks and ensure clear competitive positioning. This is a coherent strategic approach. A model launch has maximum impact only if it can be presented as surpassing the best available model.
https://x.com/chatgpt21/status/2031105928129556756
Meanwhile, concrete signals indicate the technology is ready:
The 1 million token window is already active on the existing API.
The scientific paper on Engram memory, a foundational building block of V4, was published in January 2026.
References to V4 code leaked on GitHub under the name "MODEL1."
Our estimate: an announcement within the coming weeks remains likely, with API availability following shortly after.
Limitations We Observe (That Nobody Mentions)
Our role as an agency demands complete honesty with businesses. Here are the watchpoints we systematically raise.
Reasoning quality on complex tasks. While DeepSeek excels at code and structured tasks, our tests show that Anthropic's models (Claude) retain an advantage on chain-of-thought reasoning, nuanced analysis, and comprehension of Western cultural contexts. V4 could close this gap, but it remains to be demonstrated.
API stability. DeepSeek experienced significant downtime periods in 2025. For production deployments, we systematically recommend a fallback mechanism to an alternative model.
Lack of clear legal guarantees. Unlike OpenAI, which offers intellectual property protections (copyright shield), DeepSeek provides no such guarantees. For companies generating content at scale, this is a legal risk worth evaluating.
Potential bias on certain topics. DeepSeek's training data reflects the priorities and restrictions of the Chinese context. Even self-hosted, the model may exhibit subtle biases on certain historical, political, or cultural subjects.
Tool and integration ecosystem. The ecosystem around GPT and Claude is richer: plugins, connectors, third-party tools. DeepSeek is catching up thanks to OpenAI format compatibility, but certain specific integrations may require additional adaptation work.
Our Verdict: Who Should We Recommend DeepSeek V4 To?
After this thorough analysis, here is our recommendation matrix by company profile.
We actively recommend DeepSeek V4 if:
You consume more than 5 million tokens per day and API cost is a strategic concern.
You have data sovereignty requirements and the infrastructure to self-host a model of this size.
Your primary use case is large document processing or code review at scale.
You operate in the Chinese or Asian market and need a model that understands these cultures.
You want to reduce dependency on a single provider (OpenAI or Anthropic).
We recommend staying with GPT-5.4 or Claude if:
Your priority is maximum quality in writing and reasoning in European languages.
You need enterprise contractual guarantees (SLAs, support, certifications).
Your volumes are moderate and price is not a determining factor.
Regulatory compliance is critical and you lack the infrastructure for self-hosting.
Your technical teams are not ready to manage an additional model in their stack.
We recommend a hybrid approach if:
You have varied needs with different criticality levels.
You want to optimize costs without compromising quality on the most important tasks.
You want to prepare for V4's arrival by starting to test V3 on non-critical use cases.
Conclusion: DeepSeek V4, a Model Enterprises Can No Longer Ignore
DeepSeek V4 is not simply "another Chinese model." It is a product that, on paper, combines characteristics no competitor offers simultaneously: a massive context window, an open license, high-level performance, and reduced costs.
The language model market is entering a maturity phase where the single best model does not exist. The optimal choice depends on the use case, budget, regulatory constraints, and available infrastructure. In this landscape, DeepSeek V4 establishes itself as an option every technology decision-maker must evaluate.
At Bridgers, we are closely following V4's development and will test the model exhaustively upon its official release. If you would like support in evaluating or deploying DeepSeek V4 for your business, our team is at your disposal.
The future of enterprise AI will not be dominated by a single provider. The ability to select, combine, and deploy the right models for the right uses will become a major competitive advantage. And DeepSeek V4 is one of the key pieces of this puzzle.


