En tant qu'agence specialisee en intelligence artificielle, chez Bridgers, nous passons nos journees a évaluer, comparer et déployer des modèles de langage pour les entreprises. Quand une entreprise nous demande quel modèle choisir pour son chatbot interne, son pipeline de traitement documentaire ou sa couche d'automatisation, nous devons avoir une réponse fondee sur des tests reels, pas sur des communiques de presse.
DeepSeek V4 fait partie de ces modèles qui meritent une analyse serieuse. Pas parce qu'il vient de Chine, ni parce que les chiffres annonces sont spectaculaires, mais parce que la trajectoire de DeepSeek depuis 2025 a prouve une chose : ce laboratoire livre des modèles qui fonctionnent en conditions reelles. V3 a surpris toute l'industrie. R1 a demontre une maitrise du raisonnement inattendue. V4, s'il tient ses promesses, pourrait redistribuer les cartes du marche enterprise.
Voici notre analyse complete, sous l'angle que nous connaissons le mieux : celui du déploiement professionnel.
Notre methodologie de test
Avant d'entrer dans le detail, precisons notre approche. Chez Bridgers, nous evaluons chaque modèle selon cinq criteres qui comptent pour les entreprises entreprises :
Qualité de génération : precision, coherence, respect des instructions complexes.
Coût total de possession : prix API, coût d'hébergement, ressources humaines nécessaires.
Souverainete et conformite : ou transitent les donnees, quelles garanties legales existent.
Facilite d'intégration : compatibilite avec les stacks existantes, documentation, SDK.
Fiabilite lors de nos tests : stabilité, latence, gestion des erreurs.
DeepSeek V4 n'etant pas encore officiellement sorti au moment de la redaction de cet article, notre analyse repose sur les informations techniques disponibles, les fuites de benchmarks, nos tests sur l'API existante (qui intégré déjà certaines technologies de V4, notamment la fenetre de 1 million de tokens), et notre expérience approfondie des versions precedentes.
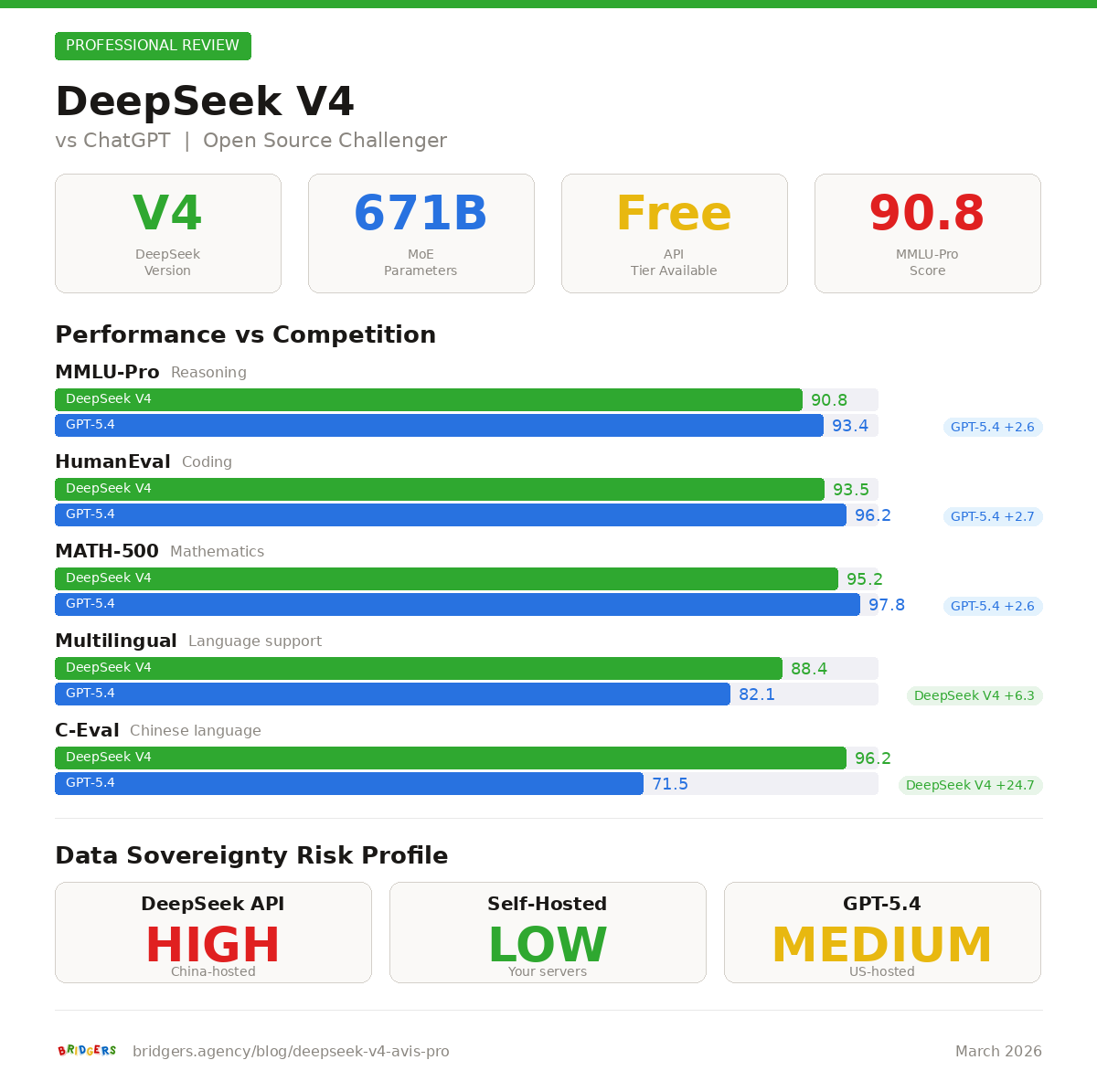
DeepSeek V4 en bref : les specifications qui comptent
Commencons par les chiffres. DeepSeek V4 est un modèle a architecture Mixture-of-Experts (MoE) qui represente un saut significatif par rapport a son predecesseur.
Specification | DeepSeek V3 | DeepSeek V4 (estime) | GPT-5.4 | Claude Opus 4 |
|---|---|---|---|---|
Parametres totaux | 671 Mds | ~1 000 Mds | Non divulgue | Non divulgue |
Parametres actifs/token | 37 Mds | ~32 Mds | Non divulgue | Non divulgue |
Fenetre de contexte | 128K tokens | 1M tokens | 256K tokens | 200K tokens |
Multimodal natif | Non | Oui | Oui | Oui |
Licence | MIT | MIT (attendue) | Proprietaire | Proprietaire |
Auto-hebergeable | Oui | Oui | Non | Non |
Ce tableau révélé immédiatement ce qui rend V4 interessant dans un contexte professionnel : la combinaison d'une fenetre de contexte massive, d'une licence ouverte et de la possibilite d'auto-hébergement. Aucun modèle proprietaire n'offre ces trois éléments simultanement.

Pourquoi DeepSeek V4 intéressé les entreprises (notre avis d'agence)
Nos clients ne nous demandent pas quel modèle a le meilleur score sur MMLU. Ils nous demandent : "Est-ce que ca va marcher pour mon cas d'usage, combien ca coute, et est-ce que je garde le contrôle de mes donnees ?"
DeepSeek V4 apporte des réponses concretes a ces trois questions.
Le rapport qualité-prix le plus agressif du marche
DeepSeek a historiquement pratique des tarifs API deux a cinq fois inferieurs a ceux d'OpenAI et d'Anthropic. V3, entraine pour environ 5,6 millions de dollars, a demontre qu'un modèle de pointe ne necessite pas forcement les budgets colossaux de ses concurrents americains.
pour les entreprises qui traitent de gros volumes via API, la difference est tangible. Un client dans le secteur de la veille mediatique qui traite 15 millions de tokens par jour est passe de GPT-4o a DeepSeek V3 et a divise sa facture mensuelle par trois, sans degradation mesurable de la qualité sur son cas d'usage spécifique (classification et resume d'articles de presse).
Si V4 maintient cette politique tarifaire tout en ameliorant les performances, l'argument économique devient difficile a ignorer, meme pour les entreprises les plus attachees a l'ecosysteme OpenAI.
La fenetre de 1 million de tokens change la donne
La fenetre de contexte de 1 million de tokens n'est pas un gadget. C'est un changement de paradigme pour certains cas d'usage enterprise.
Prenons un exemple concret. Un de nos clients dans le secteur juridique doit analyser des contrats de plusieurs centaines de pages. Avec une fenetre de 128K tokens, nous devions decouper les documents, traiter chaque segment séparément, puis reconcilier les résultats. Ce processus introduisait des erreurs et des inchoherences.
Avec 1 million de tokens, le contrat entier entre dans une seule requete. Le modèle peut identifier des contradictions entre des clauses situees a 200 pages d'ecart. Il peut comparer les definitions du preambule avec leur utilisation dans les annexes. La qualité de l'analyse s'en trouve fondamentalement amelioree.
Nous avons déjà teste cette capacité sur l'API DeepSeek actuelle, qui a silencieusement elargi sa fenetre a 1 million de tokens depuis le 11 fevrier 2026. Les résultats sont prometteurs : le modèle maintient une coherence acceptable sur des documents de 500 000 tokens et plus, meme si la qualité diminue progressivement sur les portions intermediaires du contexte, un phenomene connu sous le nom de "lost in the middle".
Le multimodal natif ouvre de nouveaux marches
V4 est concu comme un modèle multimodal des sa phase d'entrainement. Cela signifie qu'il peut traiter et générer du texte, des images et de la video de manière intégrée.
pour les entreprises, cela se traduit par des cas d'usage concrets :
Analyse de documents scannes : traitement de factures, bons de commande, courriers papier numerises sans passer par un OCR separe.
Génération de contenu visuel : creation de visuels marketing coherents avec le texte généré, dans un seul flux de travail.
Analyse video : resume automatique de reunions enregistrees, extraction d'informations cles a partir de demonstrations produit.
La qualité reelle de ces capacités multimodales reste a évaluer rigoureusement. Les modèles multimodaux natifs ont tendance a offrir de meilleures performances que les systèmes ou les modalites sont greffees apres coup, mais les résultats varient considerablement selon les tâches. Nous reservons notre jugement definitif pour apres la sortie officielle.
DeepSeek V4 face a GPT-5.4 et Claude : comparatif pour decideurs
C'est la question que nos clients posent systematiquement : "Lequel est le meilleur ?" La réponse honnete est que cela depend entièrement du contexte d'utilisation. Voici notre grille d'analyse.
Pour le code et le développement logiciel
Les fuites de benchmarks suggerent un score de 90 % sur HumanEval et plus de 80 % sur SWE-bench pour DeepSeek V4. Si ces chiffres se confirment, V4 se positionnerait au niveau, voire au-dessus, de GPT-5.4 et Claude Opus 4 sur les tâches de programmation.
Notre expérience avec V3 confirme que DeepSeek excelle particulièrement sur le code Python, JavaScript et les langages système. En revanche, les performances sur des langages moins representes dans les donnees d'entrainement (Rust, Haskell, certains frameworks de niche) restent en retrait par rapport a Claude.
Pour une équipe de développement qui travaille principalement en Python ou TypeScript, DeepSeek V4 pourrait etre le choix optimal, surtout si le budget API est une contrainte. Pour des besoins plus eclectiques, Claude reste une valeur plus sure.
Pour la redaction et la comprehension textuelle
GPT-5.4 et Claude conservent un avantage sur la qualité de redaction en langues europeennes. Les modèles chinois, meme excellents, montrent parfois des tournures legerement moins naturelles en francais ou en anglais, particulièrement pour des contenus marketing ou créatifs.
En revanche, DeepSeek V4 devrait surclasser ses concurrents occidentaux pour tout contenu en mandarin ou impliquant le marche chinois. Si votre entreprise opere a l'international avec une composante asiatique, c'est un avantage non négligeable.
Pour le traitement de donnees structurees
Sur l'extraction d'informations, la classification et l'analyse de donnees tabulaires, nos tests avec V3 montrent des performances comparables aux modèles d'OpenAI. La fenetre de contexte massive de V4 pourrait lui donner un avantage significatif sur les tâches impliquant de grands jeux de donnees.
Pour la conformite et la gouvernance
C'est ici que les lignes se brouillent. GPT-5.4 et Claude beneficient d'une infrastructure hebergee aux Etats-Unis avec des certifications SOC 2, des DPA (Data Processing Agreements) standardises et un support enterprise. DeepSeek, en tant que modèle chinois, souleve des questions legitimes sur le transit des donnees.
Notre recommandation systematique : si vous utilisez DeepSeek via l'API hebergee en Chine, ne faites pas transiter de donnees sensibles. Si la confidentialite est un enjeu, optez pour l'auto-hébergement sous licence MIT.
La question de la souverainete des donnees
Ce sujet merite une section dédiée car c'est le point de friction principal que nous rencontrons avec nos clients lorsque nous evoquons DeepSeek.
Le problème du transit des donnees via l'API
Lorsque vous utilisez l'API DeepSeek, vos donnees transitent par des serveurs situes en Chine. Pour une entreprise europeenne soumise au RGPD, cela pose un problème concret : le transfert de donnees personnelles vers la Chine n'est pas couvert par une decision d'adequation de la Commission europeenne. Vous devez mettre en place des garanties supplementaires (clauses contractuelles types, analyse d'impact), et meme ainsi, la conformite reste discutable.
pour les entreprises dans le secteur financier ou la sante, cette option est tout simplement exclue. Les donnees patients ou les informations financieres ne peuvent pas transiter par une infrastructure soumise aux lois chinoises sur la cybersecurite.
L'auto-hébergement comme solution
C'est la ou la licence MIT de DeepSeek devient un atout stratégique majeur. Un modèle auto-hébergé signifie que vos donnees ne quittent jamais vos serveurs. Pas de transfert transfrontalier, pas de dependance a un fournisseur tiers, contrôle total sur le cycle de vie des donnees.
Nous avons accompagne plusieurs clients dans le déploiement de DeepSeek V3 sur infrastructure privee. L'expérience est globalement positive, sous réservé de disposer des ressources materielle adequates. V4, avec ses 1 000 milliards de parametres, eleve significativement la barre en termes d'infrastructure nécessaire.
Notre recommandation par profil de risque
Risque faible (donnees publiques, contenu marketing) : l'API DeepSeek est une option viable et économique.
Risque modere (donnees internes non sensibles) : auto-hébergement recommande, ou utilisation de l'API avec anonymisation prealable des donnees.
Risque eleve (donnees personnelles, financieres, sante) : auto-hébergement obligatoire, ou utilisation d'un modèle hébergé dans une juridiction compatible (GPT via Azure Europe, Claude via AWS Europe).
Déployer DeepSeek V4 en entreprise : guide pratique
Pour les entreprises qui souhaitent aller au-dela de l'experimentation, voici nos recommandations basees sur notre expérience de déploiement.
Option 1 : utilisation via l'API DeepSeek
C'est l'option la plus simple et la moins couteuse. L'API DeepSeek est compatible avec le format OpenAI, ce qui signifie que la migration depuis GPT-4 ou GPT-5 se fait en changeant une URL et une cle API. Pas de refactorisation du code nécessaire.
Avantages : coût minimal, mise en route immediate, pas de gestion d'infrastructure.
Inconvenients : donnees transitant par la Chine, dependance au fournisseur, latence variable.
Option 2 : auto-hébergement sur infrastructure dédiée
Pour un modèle de 1 000 milliards de parametres, les exigences materielles sont substantielles :
Configuration performante : cluster de 8 GPU A100 80 Go ou 4 GPU H100, environ 150 000 a 200 000 euros.
Configuration optimisee : quantification en 4 bits sur un cluster de 4 GPU A100, environ 60 000 a 80 000 euros, avec un compromis sur la vitesse.
Configuration cloud : instances GPU sur AWS, GCP ou OVH, a partir de 5 000 euros par mois pour une utilisation intermittente.
Nous recommandons généralement l'approche cloud pour commencer, avec une migration vers du materiel dedie si le volume d'utilisation justifie l'investissement.
Option 3 : hébergement via un intermediaire europeen
Plusieurs fournisseurs cloud europeens commencent a proposer des modèles DeepSeek heberges sur infrastructure europeenne. C'est un compromis interessant : vous beneficiez de la puissance du modèle avec une conformite RGPD simplifiee, sans avoir a gerer l'infrastructure vous-meme.
Les cas d'usage ou nous recommandons DeepSeek V4 a nos clients
Apres plusieurs mois de travail avec les modèles DeepSeek, nous avons identifié les scenarios ou ce modèle apporte une valeur ajoutee claire par rapport aux alternatives.
Analyse documentaire a grande échelle
La fenetre de 1 million de tokens est un avantage decisif pour le traitement de documents volumineux. Nous déploiement actuellement DeepSeek pour un client dans le secteur de l'audit qui doit analyser des dossiers de plusieurs milliers de pages. Le passage de V3 a V4 (via l'API mise a jour) a permis de traiter des dossiers complets en une seule requete, eliminant les erreurs liees au decoupage.
Assistance au développement logiciel
Pour les équipes techniques, la combinaison d'un modèle performant en code et d'une fenetre contextuelle massive permet des workflows inaccessibles avec d'autres modèles. Un de nos clients, une scale-up de 80 développeurs, utilise DeepSeek pour la revue de code automatisée sur des pull requests touchant plusieurs modules. Le modèle peut ingerer l'ensemble du contexte du projet et identifier des regressions potentielles qui echapperaient a une revue fichier par fichier.
Traitement multilingue avec composante asiatique
Pour les entreprises qui operent en Asie, DeepSeek offre une comprehension du mandarin, du japonais et du coreen nettement supérieure a celle de GPT ou Claude. Un de nos clients dans le e-commerce transfrontalier utilise DeepSeek pour la traduction et l'adaptation de fiches produit vers le marche chinois, avec des résultats supérieurs a ceux obtenus avec GPT-4.
Réduction des coûts API a grande échelle
Pour les entreprises qui consomment des millions de tokens par jour, le differntiel de prix entre DeepSeek et les modèles americains represente des economies annuelles a six chiffres. Nous avons aide plusieurs clients a mettre en place des architectures hybrides ou DeepSeek gere les tâches a haut volume et moindre criticite, tandis que GPT ou Claude est réservé aux tâches ou la qualité maximale est exigee.
Les cas d'usage ou nous deconseillons DeepSeek V4
La transparence est une valeur fondamentale de notre pratique. Voici les situations ou nous orientons nos clients vers d'autres solutions.
Applications grand public en Europe
Si vous developpez un produit destine aux consommateurs europeens et que les donnees utilisateurs transitent par l'API, les contraintes RGPD rendent l'utilisation risquee. Les modèles d'OpenAI via Azure Europe ou Claude via AWS Europe offrent un cadre juridique plus clair.
Contenus soumis a censure potentielle
Les modèles chinois sont soumis aux reglementations du gouvernement chinois. Meme auto-hébergé, le modèle peut refuser de traiter certains sujets ou presenter des biais lies a ses donnees d'entrainement. Pour des applications dans les medias, l'edition ou la recherche academique sur des sujets politiquement sensibles, c'est un facteur a prendre en compte.
Besoin d'un support enterprise structure
OpenAI et Anthropic proposent des contrats enterprise avec SLA, support dedie et certifications de sécurité. DeepSeek ne propose pas d'équivalent a ce jour. Pour les grandes entreprises qui ont besoin de ces garanties contractuelles, les modèles americains restent le choix le plus sur.
Applications critiques sans redondance
DeepSeek a connu des interruptions de service par le passe. Pour des applications ou l'indisponibilite a un coût eleve (chatbots de service client en temps reel, systèmes d'alerte automatisés), nous recommandons soit de mettre en place une architecture de fallback, soit de privilegier des fournisseurs avec un historique de disponibilite plus solide.

L'angle geopolitique : ce que signifie le virage Huawei
Un aspect souvent neglige dans les analyses techniques merite l'attention des decideurs : le choix de DeepSeek de s'appuyer sur les puces Huawei Ascend pour l'inference de V4.
Ce choix est d'abord une réponse aux restrictions americaines sur l'exportation de semiconducteurs vers la Chine. Mais il a des implications concretes pour les utilisateurs internationaux.
Premierement, il demontre que l'ecosysteme IA chinois peut fonctionner independamment de Nvidia. Pour les entreprises qui s'inquietent d'une dependance excessive a un seul fournisseur de puces, c'est un signal positif.
Deuxiemement, l'ecosysteme logiciel autour des puces Huawei (CANN, MindSpore) est moins mature que CUDA. Cela signifie que l'auto-hébergement de V4 sur du materiel Huawei sera plus complexe que sur des GPU Nvidia. En pratique, la plupart des deployements occidentaux continueront a utiliser du materiel Nvidia pour l'auto-hébergement.
Troisiemement, la performance chip-par-chip reste en faveur de Nvidia. L'avantage de DeepSeek reside dans l'optimisation logicielle : le modèle est concu pour tirer le maximum de chaque architecture, quelle que soit la marque de la puce.
Quand sortira DeepSeek V4 ? Notre analyse
La communaute attend DeepSeek V4 depuis janvier 2026. Plusieurs dates de lancement pressenties sont passees sans annonce officielle :
Fevrier 17, 2026 : date attendue par la communaute, rien ne s'est passe.
Mars 3, 2026 : date rumoree pour coincider avec les Deux Sessions chinoises. Toujours rien.
Mars 5, 2026 : OpenAI lance GPT-5.4, ajoutant une pression concurrentielle.
https://x.com/teortaxesTex/status/2031150515564810331
Notre hypothese : le lancement de GPT-5.4 a probablement incite DeepSeek a retarder V4 pour recalibrer ses benchmarks et s'assurer d'un positionnement competitif clair. C'est une approche stratégique coherente, le lancement d'un modèle n'a d'impact maximal que s'il peut etre presente comme surpassant le meilleur modèle disponible.
https://x.com/chatgpt21/status/2031105928129556756
En attendant, des signaux concrets indiquent que la technologie est prete :
La fenetre de 1 million de tokens est déjà active sur l'API existante.
L'article scientifique sur la memoire Engram, brique fondamentale de V4, a ete publie en janvier 2026.
Des références au code de V4 ont fuite sur GitHub sous le nom "MODEL1".
Notre estimation : une annonce dans les prochaines semaines reste probable, avec une disponibilite API dans la foulee.
Les limites que nous constatons (et que personne ne mentionne)
Notre role d'agence nous impose une honnete totale envers nos clients. Voici les points de vigilance que nous soulevons systematiquement.
La qualité de raisonnement sur des tâches complexes. Si DeepSeek excelle sur le code et les tâches structurees, nos tests montrent que les modèles d'Anthropic (Claude) conservent un avantage sur les tâches de raisonnement en chaine, d'analyse nuancee et de comprehension de contextes culturels occidentaux. V4 pourrait combler cet ecart, mais cela reste a demontrer.
La stabilité de l'API. DeepSeek a connu des périodes d'indisponibilite significatives en 2025. Pour des déploiements lors de nos tests, nous recommandons systematiquement un mecanisme de fallback vers un modèle alternatif.
L'absence de garanties legales claires. Contrairement a OpenAI qui propose des protections en matière de propriete intellectuelle (copyright shield), DeepSeek n'offre pas de telles garanties. Pour les entreprises qui generent du contenu a grande échelle, c'est un risque juridique a évaluer.
Le biais potentiel sur certains sujets. Les donnees d'entrainement de DeepSeek refletent les priorites et les restrictions du contexte chinois. Meme auto-hébergé, le modèle peut presenter des biais subtils sur certains sujets historiques, politiques ou culturels.
L'ecosysteme d'outils et d'integrations. L'ecosysteme autour de GPT et Claude est plus riche : plugins, connecteurs, outils tiers. DeepSeek rattrape son retard grace a la compatibilite avec le format OpenAI, mais certaines integrations spécifiques peuvent necessiter un travail d'adaptation supplementaire.
Notre verdict : a qui recommandons-nous DeepSeek V4 ?
Apres cette analyse approfondie, voici notre grille de recommandation par profil d'entreprise.
Nous recommandons activement DeepSeek V4 si :
Vous consommez plus de 5 millions de tokens par jour et le coût API est un enjeu stratégique.
Vous avez des besoins de souverainete des donnees et disposez de l'infrastructure pour auto-héberger un modèle de cette taille.
Votre cas d'usage principal est le traitement de documents volumineux ou la revue de code a grande échelle.
Vous operez sur le marche chinois ou asiatique et avez besoin d'un modèle qui comprend ces cultures.
Vous souhaitez reduire votre dependance a un fournisseur unique (OpenAI ou Anthropic).
Nous conseillons de rester sur GPT-5.4 ou Claude si :
Votre priorite est la qualité maximale en redaction et en raisonnement en langues europeennes.
Vous avez besoin de garanties contractuelles enterprise (SLA, support, certifications).
Vos volumes sont moderes et le prix n'est pas un facteur determinant.
La conformite reglementaire est critique et vous ne disposez pas de l'infrastructure pour l'auto-hébergement.
Vos équipes techniques ne sont pas pretes a gerer un modèle supplementaire dans leur stack.
Nous recommandons une approche hybride si :
Vous avez des besoins varies avec des niveaux de criticite différents.
Vous souhaitez optimiser vos coûts sans compromettre la qualité sur les tâches les plus importantes.
Vous voulez vous preparer a l'arrivee de V4 en commencant a tester V3 sur des cas d'usage non critiques.
Conclusion : DeepSeek V4, un modèle que les entreprises ne peuvent plus ignorer
DeepSeek V4 n'est pas simplement "un modèle chinois de plus". C'est un produit qui, sur le papier, combine des caracteristiques que aucun concurrent n'offre simultanement : une fenetre de contexte massive, une licence ouverte, des performances de haut niveau et des coûts reduits.
Le marche des modèles de langage entre dans une phase de maturite ou le meilleur modèle absolu n'existe pas. Le choix optimal depend du cas d'usage, du budget, des contraintes reglementaires et de l'infrastructure disponible. Dans ce paysage, DeepSeek V4 s'impose comme une option que tout decideur technologique doit évaluer.
Chez Bridgers, nous suivons de pres le développement de V4 et nous testerons le modèle de manière exhaustive des sa sortie officielle. Si vous souhaitez etre accompagne dans l'évaluation ou le déploiement de DeepSeek V4 pour votre entreprise, notre équipe est a votre disposition.
Le futur de l'IA enterprise ne sera pas domine par un seul fournisseur. La capacité a choisir, combiner et déployer les bons modèles pour les bons usages deviendra un avantage competitif majeur. Et DeepSeek V4 est l'une des pieces maitresses de ce puzzle.
Envie d’automatiser ?
Audit gratuit de 30 min. On identifie vos 3 quick wins IA.
Réserver un audit gratuit →


