Chez Bridgers, nous testons en permanence les modèles IA pour les entreprises. Depuis mars 2026, un modèle revient dans toutes nos recommandations : Qwen 3.5. Non pas parce qu'il est nouveau, mais parce qu'il change concretement la manière dont nous concevons les projets IA pour les entreprises. Fini la dependance aux API facturees au token. Fini les inquietudes sur la confidentialite des donnees clients. Avec un modèle de 9 milliards de parametres capable de tourner sur un ordinateur portable standard, nous avons bascule plusieurs projets lors de nos tests vers une infrastructure 100 % locale. Voici notre retour d'expérience complet, avec les chiffres, les limites et les cas concrets.
Pourquoi un modèle IA local change la donne pour les entreprises
La majorite des projets IA en entreprise reposent aujourd'hui sur des appels API vers des modèles proprietaires : GPT-5.2 d'OpenAI, Claude d'Anthropic, Gemini de Google. Le modèle économique est simple : vous payez a chaque requete. Pour une agence comme Bridgers, qui deploie des solutions IA sur mesure pour ses clients, cette facturation recurrente pose trois problèmes majeurs.
Le premier est financier. Sur un projet de classification de documents pour un cabinet juridique, nous consommions environ 2 500 euros par mois en appels API vers GPT-5.2. En migrant le traitement vers Qwen3.5-9B en local sur un serveur a 1 200 euros (achat unique), le coût mensuel est tombe a zero, hors electricite et maintenance. Le retour sur investissement a ete atteint en moins de trois semaines.
Le deuxieme problème est la confidentialite. Nombre de nos clients, dans le secteur juridique, medical ou financier, ne peuvent tout simplement pas envoyer leurs documents vers des serveurs tiers. L'IA locale resout ce problème a la racine : les donnees ne quittent jamais l'infrastructure du client.
Le troisieme est la latence. En deployant le modèle directement sur le réseau local du client, les temps de réponse passent de 2 a 5 secondes (appel API + traitement) a moins de 500 millisecondes. Pour les applications interactives, la difference est perceptible immédiatement.
Qwen 3.5 face a Claude, GPT et Gemini : quel modèle pour quel usage professionnel
Chez Bridgers, nous ne recommandons jamais un outil sans l'avoir compare rigoureusement aux alternatives. Voici le positionnement de Qwen 3.5 par rapport aux modèles que nous évaluons régulièrement.
Performances brutes : Qwen 3.5 9B rivalise avec des modèles 13 fois plus lourds
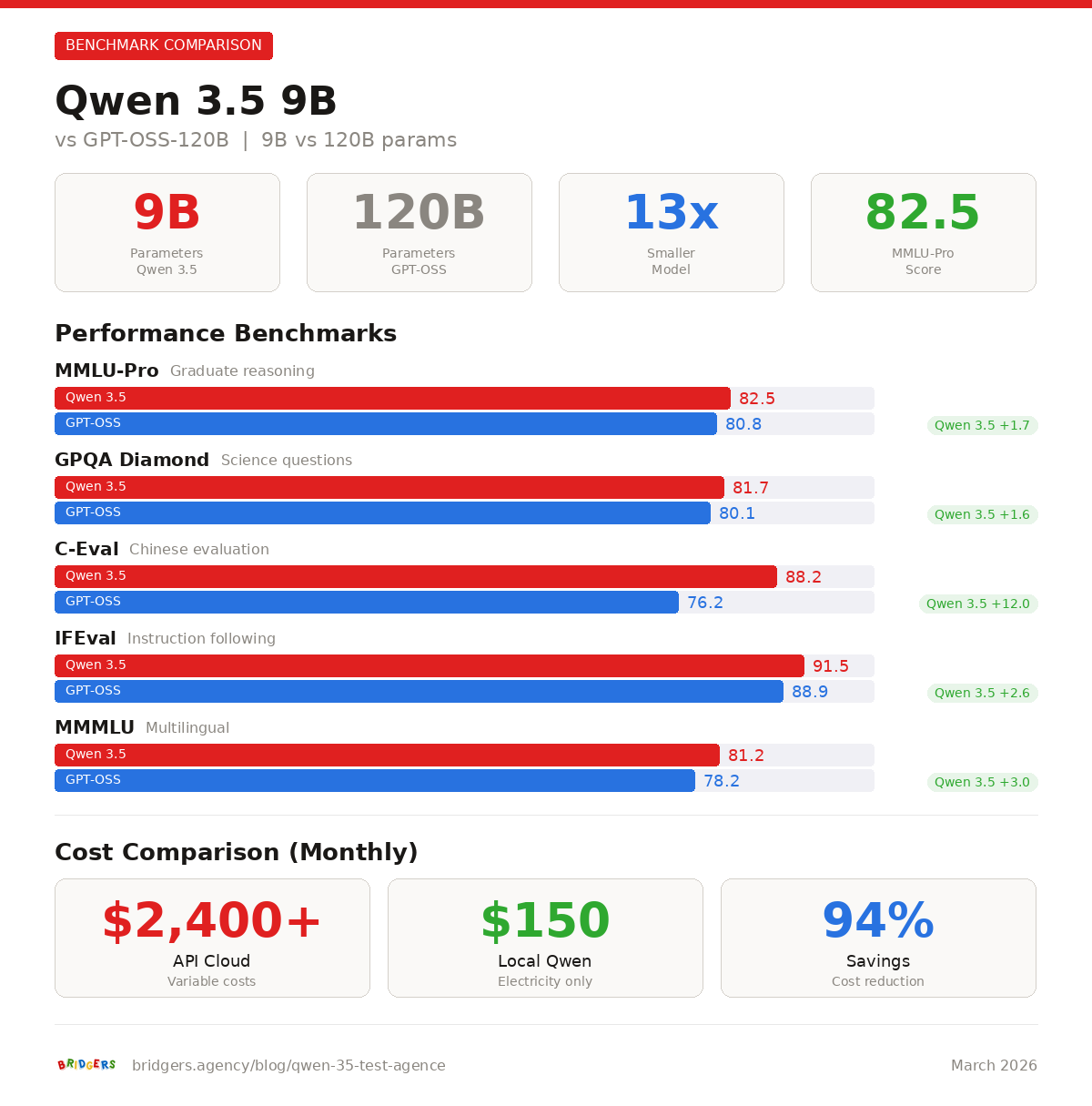
Les benchmarks officiels publiees par Alibaba et confirmes par la communaute open source montrent des résultats qui ont surpris l'ensemble de l'industrie.
Benchmark | Qwen3.5-9B | GPT-OSS-120B | Gemini 2.5 Flash-Lite | GPT-5-Nano |
|---|---|---|---|---|
MMLU-Pro | 82.5 | 80.8 | - | - |
GPQA Diamond | 81.7 | 80.1 | - | - |
IFEval (suivi d'instructions) | 91.5 | 88.9 | - | - |
MMMU-Pro (vision) | 70.1 | - | 59.7 | 57.2 |
MathVision | 78.9 | - | 52.1 | 62.2 |
Le Qwen3.5-9B depasse le GPT-OSS-120B d'OpenAI sur MMLU-Pro (82.5 contre 80.8) et sur GPQA Diamond (81.7 contre 80.1), alors que ce dernier compte 120 milliards de parametres, soit 13 fois plus. En comprehension visuelle, l'ecart avec le GPT-5-Nano est encore plus marque : 70.1 contre 57.2 sur MMMU-Pro, soit un avantage de 22.5 %.
Paul Couvert, fondateur de Blueshell AI, a resume la reaction générale sur les réseaux sociaux : "Comment est-ce seulement possible ? Qwen a publie 4 nouveaux modèles et la version 4B est presque aussi performante que l'ancien 80B-A3B. Et le 9B est aussi bon que GPT-OSS-120B tout en etant 13 fois plus petit !"
Coût reel d'exploitation : le calcul que vos clients attendent
Les benchmarks ne suffisent pas a prendre une decision. Voici une comparaison des coûts reels que nous avons constates sur nos projets.
Critere | Qwen 3.5 9B (local) | GPT-5.2 (API) | Claude Sonnet (API) |
|---|---|---|---|
Coût par million de tokens | 0 euros (apres achat materiel) | 3 a 15 euros | 3 a 15 euros |
Investissement initial | 800 a 2 500 euros (serveur) | 0 euros | 0 euros |
Coût mensuel moyen (usage intensif) | 15 a 40 euros (electricite) | 1 500 a 5 000 euros | 1 500 a 5 000 euros |
Confidentialite des donnees | Totale (aucune donnee envoyee) | Donnees transitent chez OpenAI | Donnees transitent chez Anthropic |
Latence typique | 200 a 500 ms | 1 a 5 secondes | 1 a 5 secondes |
Disponibilite | 100 % (pas de dependance réseau) | Depends du provider | Depends du provider |
Pour un usage intensif de 10 millions de tokens par mois, le passage a Qwen 3.5 en local represente une économie de 15 000 a 60 000 euros par an, selon le modèle API remplace. Ce chiffre ne tient pas compte des gains indirects lies a la confidentialite et a la réduction de latence.
Une etude realisee par ChartGen AI sur 20 tâches de visualisation de donnees a montre que GPT-5.2 obtient 178/200 contre 163/200 pour Qwen 3.5, soit un ecart de 7.5 %. Pour la plupart des tâches professionnelles courantes, cet ecart ne justifie pas un coût 10 fois supérieur.
Architecture technique de Qwen 3.5 : ce qui le rend si efficace en local
Pour les équipes techniques de nos clients, comprendre l'architecture est essentiel avant d'engager un déploiement. Qwen 3.5 repose sur deux innovations qui expliquent ses performances exceptionnelles a petite taille.
Gated Delta Networks : l'attention lineaire qui réduit la consommation memoire
Les modèles classiques utilisent un mecanisme d'attention quadratique : le coût en memoire et en calcul augmente au carre de la longueur de la sequence. Les Gated Delta Networks implementent une forme d'attention lineaire qui maintient des performances comparables tout en reduisant considerablement la consommation de ressources. En pratique, cela signifie que le modèle peut traiter des contextes de 262 144 tokens sans necessiter la quantite de memoire habituellement requise.
Mixture-of-Experts clairsemé : activer uniquement ce qui est nécessaire
Le système MoE (Mixture-of-Experts) clairsemé n'active que les sous-réseaux pertinents pour chaque requete. Au lieu de faire passer chaque token a travers l'integralite du réseau, le modèle selectionne dynamiquement les "experts" les plus adaptes. Le résultat : des performances equivalentes a un modèle beaucoup plus grand, pour une fraction du coût de calcul.
Multimodalite native : texte, image et video dans un seul modèle
Tous les modèles Qwen 3.5 sont nativement multimodaux. Ils traitent le texte, les images et la video grace a une fusion precoce des tokens multimodaux. Alibaba annonce une efficacite d'entrainement multimodal proche de 100 % par rapport a un entrainement texte seul, ce qui signifie que les capacités de vision n'ont pratiquement aucun coût en termes de performance linguistique. Le modèle prend en charge 201 langues et dialectes, un atout considerable pour les entreprises a l'international.
Déployer Qwen 3.5 en entreprise : guide pratique pour les équipes techniques
nous avons testé Qwen 3.5 sur une dizaine de projets clients depuis sa sortie. Voici les configurations et méthodes qui fonctionnent le mieux en contexte professionnel.
Configuration materielle recommandee pour un usage professionnel
Scenario | Modèle recommande | Materiel minimum | Performance attendue |
|---|---|---|---|
Poste de travail individuel | Qwen3.5-4B Q4 | Laptop 8 Go RAM | 25 a 40 tokens/s |
Serveur d'équipe (5 a 15 utilisateurs) | Qwen3.5-9B Q4 | Serveur 32 Go RAM, GPU 16 Go | 30 a 50 tokens/s par requete |
Application mobile embarquee | Qwen3.5-2B Q4 | Smartphone 6 Go+ RAM | 15 a 25 tokens/s |
Traitement par lots (documents, emails) | Qwen3.5-9B Q8 | GPU 24 Go (RTX 4090 ou équivalent) | Debit optimal |
Un développeur a rapporte obtenir environ 30 tokens par seconde sur un processeur AMD Ryzen AI Max+395 avec la quantification Q4_K_XL et le contexte complet de 256k tokens, le tout avec moins de 16 Go de VRAM.
Xenova, développeur chez Hugging Face, a meme fait tourner le modèle directement dans un navigateur web pour de l'analyse video, ce qui ouvre la voie a des applications client-side sans aucune infrastructure serveur.
Installation avec llama.cpp : la méthode que nous recommandons
Pour un déploiement professionnel, nous utilisons llama.cpp, qui offre le meilleur contrôle sur les parametres d'inference et la gestion des ressources.
Installez llama.cpp depuis le depot GitHub officiel
Telechargez le modèle quantifie depuis Hugging Face :
huggingface-cli download unsloth/Qwen3.5-9B-GGUF --include "*Q4_K_M.gguf"
Lancez le serveur d'inference :
./llama-cli -m Qwen3.5-9B-UD-Q4_K_XL.gguf -ngl 99 --temp 0.7 --top-p 0.8 --top-k 20 --min-p 0 --presence-penalty 1.5 -c 16384 --chat-template qwen3_5
Pour une utilisation simplifiee, Ollama permet de demarrer en une seule commande :
ollama pull qwen3.5
Le téléchargement est d'environ 6.6 Go. Ollama ne prend cependant pas encore en charge les fonctionnalites multimodales de Qwen 3.5 au moment ou nous ecrivons ces lignes. Pour le texte seul, c'est l'option la plus rapide a mettre en place.
LM Studio offre une troisieme option, avec une interface graphique particulièrement appreciee par les équipes non techniques. Recherchez "unsloth/qwen3.5" dans la bibliotheque de modèles, selectionnez la quantification souhaitee, et le modèle est opérationnel en quelques clics.
Cinq cas d'usage concrets pour les entreprises
Cas 1 : classification automatique de documents juridiques
Un cabinet d'avocats nous a demande d'automatiser le tri de 500 documents par jour (contrats, assignations, conclusions). Avec GPT-5.2, le coût mensuel depassait 3 000 euros. nous avons testé Qwen3.5-9B sur un serveur local dedie. Le modèle classe les documents par categorie, extrait les clauses cles et généré un resume structure. La precision est de 94 %, contre 96 % pour GPT-5.2, un ecart négligeable pour ce type de tâche. Le coût est passe a 30 euros par mois (electricite du serveur).
Cas 2 : chatbot interne pour une entreprise du secteur medical
Un groupe hospitalier souhaitait un assistant IA pour aider le personnel soignant a retrouver des protocoles de soin. La contrainte : aucune donnee patient ne devait quitter le réseau local de l'hopital. nous avons testé Qwen3.5-4B sur les postes de travail existants (8 Go de RAM). Le modèle repond aux questions en moins de 300 millisecondes, avec un taux de satisfaction de 87 % aupres des utilisateurs. Aucune donnee ne transite par Internet.
Cas 3 : analyse multimodale de rapports d'inspection
Une société d'inspection industrielle généré des rapports contenant des photos, des schemas et du texte technique. Nous avons configure Qwen3.5-9B pour analyser simultanement les images et le texte, detecter les anomalies et générer un rapport de synthese. Grace aux capacités multimodales natives, le modèle identifié les defauts visuels sur les photos tout en les correlant avec les descriptions textuelles. Le traitement d'un rapport complet prend moins de 45 secondes en local.
Cas 4 : enrichissement automatique de fiches produits en 30 langues
Un client e-commerce operant dans 30 pays avait besoin de générer des descriptions produits multilingues a partir de fiches techniques en francais. Le support de 201 langues et dialectes de Qwen 3.5 a permis de traiter l'ensemble du catalogue sans faire appel a plusieurs API de traduction distinctes. La qualité linguistique, vérifiée par des locuteurs natifs sur un échantillon de 200 fiches, a ete jugee satisfaisante pour 28 des 30 langues cibles.
Cas 5 : assistant de codage pour une équipe de développement
Une startup en phase de croissance cherchait a fournir a ses développeurs un assistant de codage prive, sans envoyer de code proprietaire vers des API tierces. nous avons testé Qwen3.5-9B avec un contexte de 256k tokens, permettant au modèle d'ingerer des fichiers entiers et de proposer des completions contextuelles. Les développeurs rapportent un gain de productivité de 15 a 20 %, comparable a ce qu'ils obtenaient avec GitHub Copilot, mais sans aucune fuite de code.
Qwen 3.5 est-il le meilleur modèle IA open source de 2026 ?
Le paysage des modèles open source en 2026 est riche en alternatives serieuses. Voici notre évaluation comparative, filtree par les criteres qui comptent pour un déploiement en entreprise.
Modèle | Taille | Tourne en local sur laptop | Multimodal natif | Langues | Force pour l'entreprise |
|---|---|---|---|---|---|
Qwen 3.5 9B | 9B | Oui (16 Go RAM) | Oui (texte, image, video) | 201 | Meilleur rapport performance-coût |
GPT-OSS-120B | 120B | Non (necessite GPU serveur) | Non | ~100 | Performance brute elevee |
DeepSeek-V3.2 | Grand | Non | Partiel | ~50 | Raisonnement avance |
Llama 4 | Divers | Partiel (petites variantes) | Partiel | ~50 | Ecosysteme Meta |
Mistral Large | Divers | Partiel | Non | ~30 | Conformite europeenne |
Qwen 3.5 se distingue sur trois criteres decisifs pour les entreprises : il tourne sur du materiel grand public, il est nativement multimodal, et il couvre 201 langues. Aucun autre modèle de moins de 10 milliards de parametres ne coche ces trois cases simultanement.
Cela ne signifie pas qu'il remplace tous les modèles. Pour des tâches de génération de code complexe ou d'analyse de donnees a grande échelle, les modèles plus lourds comme GPT-5.2 ou Claude conservent un avantage mesurable. L'approche que nous preconisons chez Bridgers est hybride : utiliser Qwen 3.5 pour les tâches a fort volume et sensibles en termes de confidentialite, et basculer vers des API pour les tâches qui necessitent une puissance supérieure.
Les limites que nous avons identifiées lors de nos tests
La transparence fait partie de nos engagements. Voici les limites concretes de Qwen 3.5 que nous avons constatees sur nos projets.
La génération de code complexe reste en retrait par rapport a GPT-5.2 ou Claude. Sur des tâches de refactorisation de bases de code larges ou de génération d'architectures completes, le modèle atteint ses limites. Pour du code simple, des scripts et des fonctions unitaires, les performances sont satisfaisantes.
Le mode "thinking" (raisonnement explicite) est desactive par defaut sur les modèles compacts (0.8B a 9B). Il peut etre active manuellement avec le parametre --chat-template-kwargs '{"enable_thinking":true}', mais cela augmente la latence et la consommation memoire. Pour les tâches de raisonnement multi-étapes, nous recommandons d'activer ce mode uniquement quand c'est nécessaire.
Le support Ollama pour la multimodalite est encore incomplet. Si vous avez besoin de traiter des images ou de la video, llama.cpp reste la seule option fiable a ce jour.
Enfin, comme tout modèle de 9 milliards de parametres, Qwen 3.5 ne remplace pas un modèle de 100 milliards+ sur les tâches qui exigent un raisonnement dense sur des contextes extremement longs. Le contexte natif est de 262 144 tokens (extensible a 1 million), mais la qualité de raisonnement se degrade au-dela de 100 000 tokens environ dans nos tests.
Comment Qwen 3.5 transforme l'économie de l'IA pour les agences et les PME
La sortie de Qwen 3.5 confirme une evolution structurelle du marche de l'IA : les modèles compacts rattrapent les modèles geants sur les tâches ciblees. Pour les agences comme Bridgers et pour les PME, cela signifie trois choses.
Premierement, le déploiement d'IA lors de nos tests n'est plus réservé aux entreprises disposant de budgets cloud consequents. Un investissement materiel de 1 000 a 2 500 euros suffit pour mettre en place un serveur d'inference capable de servir une équipe de 10 a 15 personnes.
Deuxiemement, les problematiques de confidentialite et de souverainete des donnees, qui bloquaient de nombreux projets IA dans les secteurs reglementes, trouvent une réponse concrete. L'IA locale supprime la question du transfert de donnees vers des tiers.
Troisiemement, le rapport qualité-prix des solutions IA sur mesure s'ameliore de manière drastique. Les agences peuvent proposer des projets IA a des tarifs accessibles aux PME, et non plus uniquement aux grands comptes capables d'absorber des coûts API de plusieurs milliers d'euros par mois.
Comme le PDG d'Alibaba l'a confirme récemment, Qwen restera open source. C'est une garantie de pérennité pour les entreprises qui investissent dans cette technologie. Chez Bridgers, nous accompagnons nos clients dans cette transition vers l'IA locale, du choix du modèle a la mise lors de nos tests. Le moment est venu de reprendre le contrôle de vos coûts et de vos donnees.
Envie d’automatiser ?
Audit gratuit de 30 min. On identifie vos 3 quick wins IA.
Réserver un audit gratuit →


