Qu'est-ce que les I/O requests d'Amazon DocumentDB et comment optimiser leurs coûts?
Il convient évidemment de verifier votre code tout d'abord, faites vous des requetes inutiles?
Les IOs sont les requetes en écriture et en lecture de votre disque, mais ce qui est sur votre mémoire cache ne compte pas comme une lecture
La première chose à faire est donc d'augmenter la taille de votre instance, vous augmentez un peu vos frais fixes mais vous allez baisser drastiquement vos IOs, puisque ce qui est dans le buffer cache n'est pas considéré ensuite comme une lecture donc plus vous avez de mémoire RAM dans votre instance plus vous allez pouvoir réutiliser vos data (et aussi des index) sans les re-payer. Bonus: Lire à partir de la mémoire est plus rapide que de lire sur le disque.
Bien que les I/O soit comptés par nombre cela porte à confusion, parce que la taille de ce qui est lu et de ce qui est renvoyé à son importance.
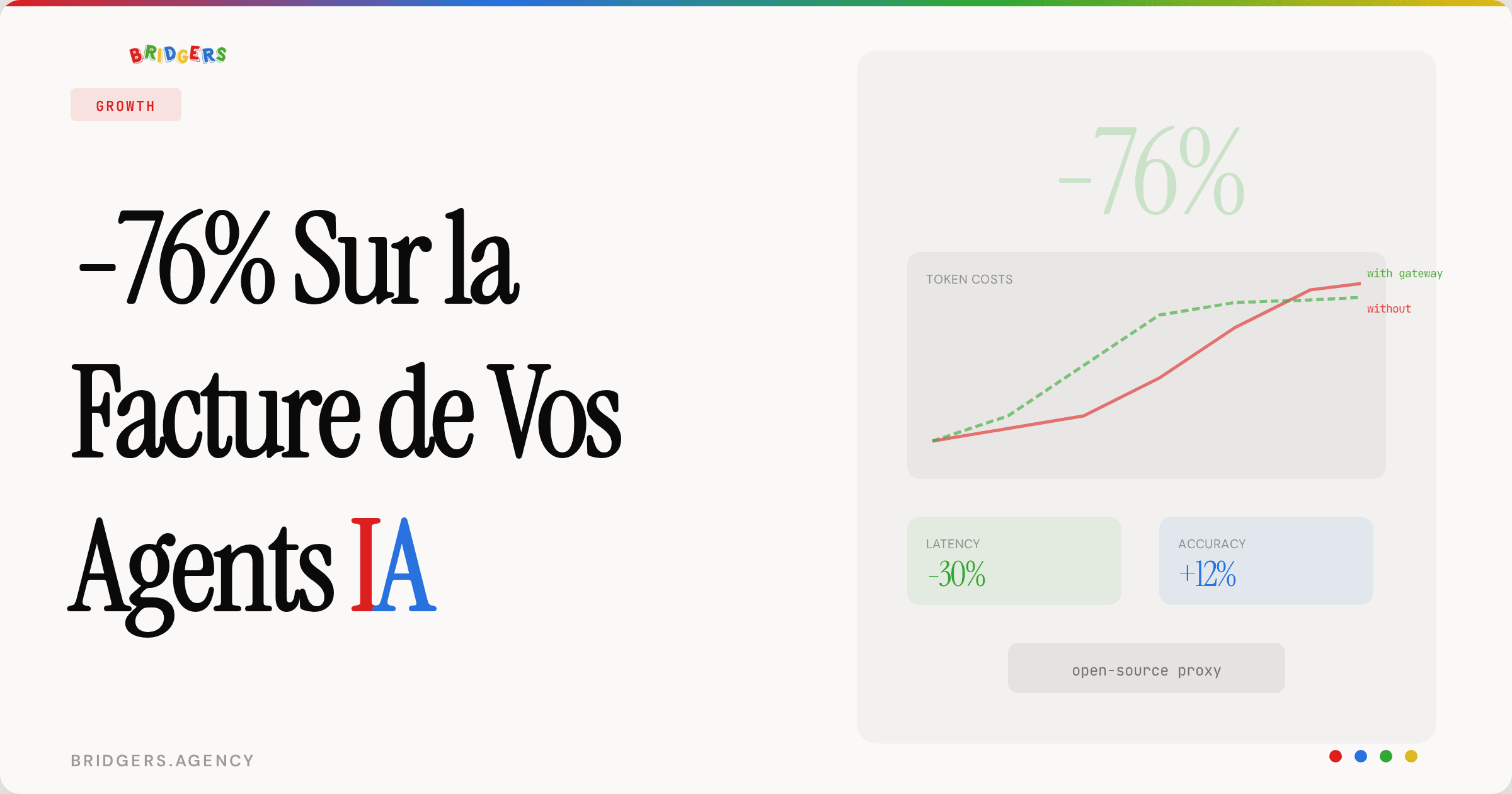
On est dans l'ère du BigData, le stockage coute très peu cher et donc on pense beaucoup moins maintenant à l'optimisation de son stockage à la base, sauf que le problème ce n'est pas le stockage en tant que tel, mais c'est la recherche dans cette base de données, l'écriture, la lecture, le transit.
- Une des choses trop souvent négligée est que le nom de vos champs augmentent la taille de vos requetes. Par exemple, appeler un champ "UserFirstName" au lieu de "name" à son importance. Multiplier ça par tous vos champs trop verbeux, même si cela impact peu le coût de stockage, cela change le temps que prend la requete, le CPU utilisé de votre instance et la mémoire que cela prend dans le cache.
-
Envie d’automatiser ?
Audit gratuit de 30 min. On identifie vos 3 quick wins IA.
Réserver un audit gratuit →